正则生成
- new RegExp 对象的构造函数
var reg = new RegExp('^[a-z]$', 'gi')
- 字面量形式:
var reg = /^[a-z]$/gi
正则的组成
元字符
- 匹配字符
. 出来换行(\n)以外的所有字符
\w 匹配字母、数字、下划线
\W 匹配除了字母、数字、下划线
\d 匹配数字
\D 匹配除了数字以外其他字符
\s 匹配仍以的空白符(空格、\t \v \n \r \f 制表符)
\S 匹配空白符意外的任意字符
- 匹配位置
\b 匹配单词开始和结束的位置(\w 和 \W 之间的位置)
\B 匹配单词的非开始或者结束位置
^ 匹配行首位置
$ 匹配行尾位置
(?=p) 该位置后面字符要匹配 p
(?!p) 该位置后面字符不匹配 p
标志字符
m 多行(multi line)
g 全局(global)
i 不区分大小写(ignore)
例如:1
2
3
4
5var reg = /^abc/;
var str = 'test\nabc'; // 匹配不上,因为 \n 是换行,不能匹配多行
var reg = /^abc/m;
var str = 'test\nabc'; // 匹配上
限定符
* 匹配 0 次以上
+ 匹配 1 次以上
? 0 次或 1 次
{m} 匹配 m 次
{ m, } 至少匹配 m 次
{m, n} 至少 m 次,最多 n 次
转义字符
*+?|\/{}[]()^$ 需要 \ 进行转义
正则方法
正则实例
test()
参数为 string,返回值为 boolean
例如:1
/javascript/.test("dadjavascript"); // true
exec()
参数string,返回 [] ,存放匹配结果,如果没有匹配上返回 null
例如:
1 | var string = "a and b and c"; |
返回值忠包含另外两个属性:index 和 input
index 表示匹配项在字符串中的位置。(上面代码匹配项为 short ,对应的位置 是16);
input 表示应用正则表达式的字符串
lastIndex
匹配的位置,可读可写
注意:
重复执行test(),他会记住匹配的位置,从上一次匹配的位置继续匹配
不具有标志 g 和不表示全局模式的正则对象不能使用 lastIndex 属性
1
2
3
4
5
6
7var reg = /abc/;
var str = '1#abc+abc';
console.log(rgb.test(str)); //true
console.log(rgb.lastIndex); // 0
console.log(rgb.test(str)); // true
console.log(rgb.lastIndex); // 0
console.log(rgb.test(str)); // truelastIndex 用于规定下次匹配的起始位置
1 | var reg = /abc/g; |
- 如果再成功匹配字符串之后,想要重新匹配新的字符串,需要将该属性设置成 0
1
2
3
4
5
6
7var reg = /abc/g;
var str = '1#abc+abc';
var str2 = '2#abc';
console.log(reg.test(str)); // true
console.log(reg.lastIndex); // 5
console.log(reg.test(str2)); // false
console.log(reg.lastIndex); // 0
字符串实例
search()
参数:需要检索的字串 / 正则对象
返回值:-1 / 字符串忠 第一个预正则相匹配的字串的位置
- 不执行全局匹配,忽略 g
- 不能使用 lastIndex
- 总是从字符串开始进行检索
1 | 'hello,javascript'.search('javascript'); //6 |
match()
参数:需要检索的字串 / 正则对象
返回值: array / null
- 如果正则没有 g ,字符串只会匹配一次
- 如果 regexp 具有标志 g,则 match() 方法将执行全局检索,找到被检索字符串中的所有匹配的子串,它 的数组元素中存放的是被检索字符串中所有的匹配的子串,而且也没有 index 属性或 input 属性;
1 | 'hello,javascript'.match('javascript'); |

replace()
替换
参数:
- 被替换的文本(字符串/正则)
- 替换成的文本(字符串/函数),如果是字符串,可以用特殊变量来代替
返回值:替换后的字符串
例如:1
2
3
4
5
6
7
8
9
10
11'hello, javascript'.replace(' javascript', 'nodejs');
'hello,javascript'.replace(/javascript/, 'nodeJs');
'javascript nodejs'.replace(/(\w+)\s(\w+)/, "$2 $1")
'javascript nodejs'.replace(/(\w+)\s(\w+)/, function( match, p1, p2, offset, string ){
// match: 匹配的字串
// p1, p2... 对应 $1 $2
// offset 匹配的字符串忠的偏移量
// string: 被匹配的字符串
console.log(match, '---', p1, p2, offset, string);
return [p1, p2].join('-')
})
$$ 插入 $
$& 插入匹配的字串
$“ 插入匹配的左侧
$” 插入撇右侧
split()
切割
- 用捕获括号的时候会将匹配结果也包含在返回的数组中。
1 | 'hello,javascript'.split(/(,)/); //["hello", ",", "javascript”] |
正则匹配
- 精确匹配:/hello/.test(‘hello’)
- 模糊匹配:
- 排除字符 ^
- 分支匹配 | (惰性)
- 分组匹配 ()
- 分组引用 $1 $2
- 反向引用 \1 \2
(正则本身引用分组,但只能引用之前出现的分组)- 括号以左开括号为准
- 引用不存在的分组,正则不会报错,只是匹配反向引用的字符串本身
- 反向分组后面量词的话,反向分组最终捕获到数据是最后一粒匹配: const reg = /(\d)+ \1/; ‘12345 1’.match(reg)
- 位置匹配
- 贪婪模式(默认)
- 非贪婪模式
再限定符后面加 ? - 捕获分组 ()
- 非捕获分组 (?:)
常用的正则
- 匹配汉字:
^[\u4e00-\u9fa5]{0,}$ - Email地址:
^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ - 日期格式:
^\d{4}-\d{1,2}-\d{1,2} - 时间:
/^(0?[0-9]|1[0-9]|[2][0-3]):(0?[0-9]|[1-5][0-9])$/ - 一年的12个月
(01~09和1~12):^(0?[1-9]|1[0-2])$ - 一个月的31天
(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$ - 中国邮政编码:
[1-9]\d{5}(?!\d) - IP地址:
((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)) - 匹配id:
'<div id="container" class="main"></div>’.match(/id="[^"]*"/ ); - 格式化货币:
function format (num) { return num.toFixed(2).replace(/\B(?=(\d{3})+\b)/, ",").replace(/^/, "$$ "); }; - 去掉左右空格:
' javascript '.replace(/^\s+|\s+$/g, ''); - 每个单词的首字母转换为大写 :
function format(str) { return str.toLowerCase().replace(/(?:^|\s)\w/g, function (c) { return c.toUpperCase(); }); } - 匹配标签:
"aaa<title>hello</title>" .match(/<([^>]+)>[\d\D]*<\/\1>/) - 身份证号码:
/^(\d{15}|\d{17}[\dxX])$/
正则的回溯
1 | '"abc"de'.match(/".*"/) |
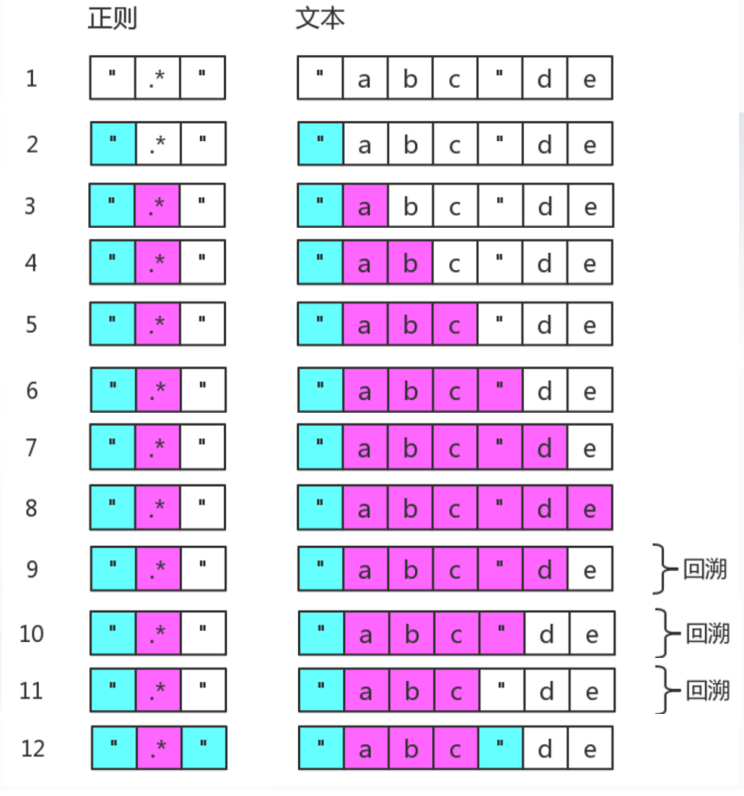
正则效率
- 使用确定的字符直接匹配
- 使用非捕获分组(省内存)
- 减少分支数量,缩减范围:/red|read/ 改为 /rea?d/
- 正则效率和正则可读性需要做一个取舍